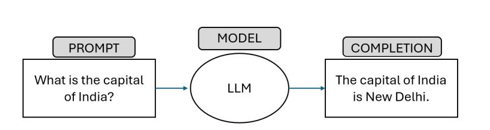
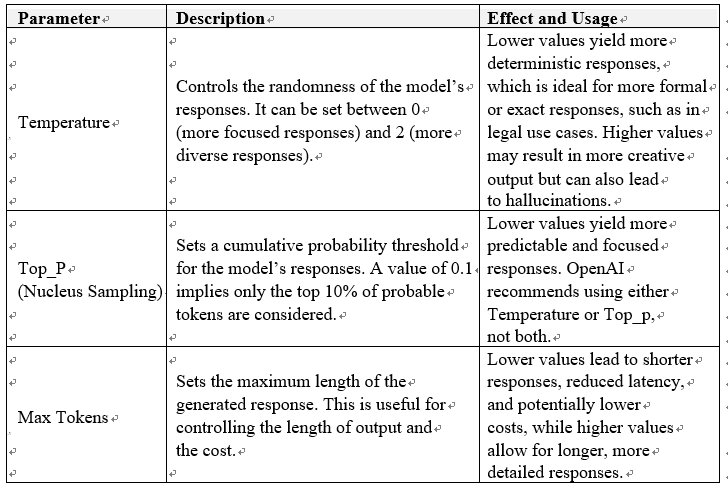
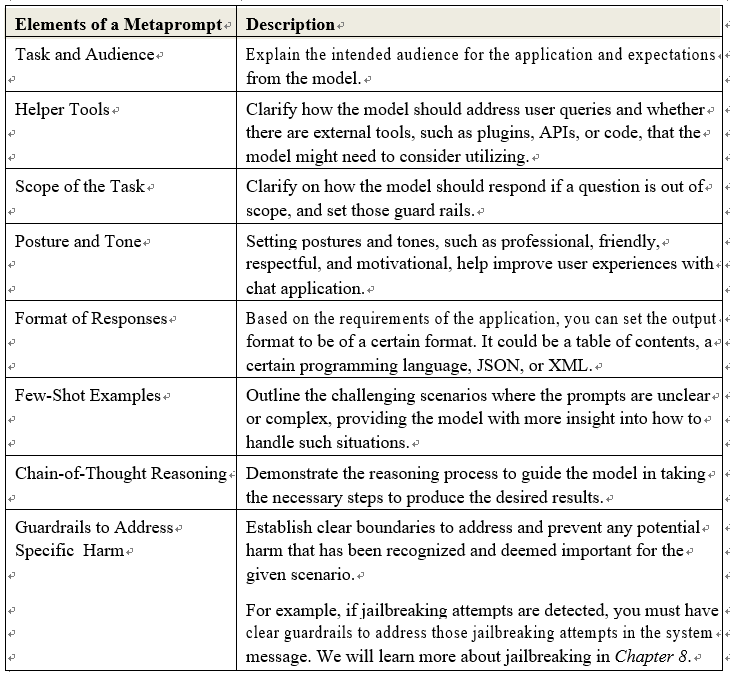
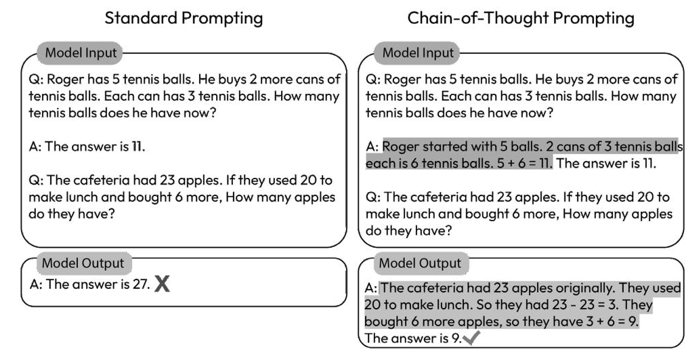
Case study – Global chat application deployment by a multinational organization
A global firm recently launched an advanced internal chat application featuring a Q&A support chatbot. This innovative tool, deployed across various Azure regions, integrates several large language models, including the specialized finance model, BloombergGPT. To meet specific organizational requirements, bespoke plugins were developed. It had an integration with Service Now, empowering the chatbot to streamline ticket generation and oversee incident actions.
In terms of data refinement, the company meticulously preprocessed its knowledge base (KB) information, eliminating duplicates, special symbols, and stop words. The KB consisted of answers to frequently asked questions and general information to various support-related questions. They employed fixed chunking approaches, exploring varied chunk sizes, before embedding these data into the Azure AI search. Their methodology utilized Azure OpenAI’s text-ada-embedding-002 models in tandem with the cosine similarity metric and Azure AI search’s vector search capabilities.
From their extensive testing, they discerned optimal results with a chunk size of 512 tokens and a 10% overlap. Moreover, they adopted an ANN vector search methodology using cosine similarity. They also incorporated hybrid search that included keyword and semantic search with Semantic Reranker. Their RAG workflow, drawing context from Azure Vector Search and the GPT 3.5 Turbo-16K models, proficiently generated responses to customer support inquiries. They implemented caching techniques using Azure Cache Redis and rate-limiting strategies using Azure API Management to optimize the costs.
The integration of the support Q&A chatbot significantly streamlined the multinational firm’s operations, offering around-the-clock, consistent, and immediate responses to queries, thereby enhancing user satisfaction. This not only brought about substantial cost savings by reducing human intervention but also ensured scalability to handle global demands. By automating tasks such as ticket generation, the firm gained deeper insights into user interactions, allowing for continuous improvement and refinement of their services.
Summary
In this chapter, we explored the RAG approach, a powerful method for leveraging your data to craft personalized experiences, reduce hallucinations while also addressing the training limitations inherent in LLMs. Our journey began with an examination of foundational concepts such as vectors and databases, with a special focus on Vector Databases. We understood the critical role that Vector DBs play in the development of RAG-based applications, also highlighting how they can enhance LLM responses through effective chunking strategies. The discussion also covered practical insights on building engaging RAG experiences, evaluating them through prompt flow, and included a hands-on lab available on GitHub to apply what we’ve learned.
In the next chapter we will introduce another popular technique designed to minimize hallucinations and more easily steer the responses of LLMs. We will cover prompt engineering strategies, empowering you to fully harness the capabilities of your LLMs and engage more effectively with AI. This exploration will provide you with the tools and knowledge to enhance your interactions with AI, ensuring more reliable and contextually relevant outputs.