The following image visually represents the clustering of mammals and birds in a two-dimensional vector embedding space, differentiating between their realistic and cartoonish portrayals. This image depicts a spectrum between “REALISTIC” and “CARTOON” representations, further categorized into “MAMMAL” and “BIRD.” On the realistic side, there’s a depiction of a mammal (elk) and three birds (an owl, an eagle, and a small bird). On the cartoon side, there are stylized and whimsical cartoon versions of mammals and birds, including a comically depicted deer, an owl, and an exaggerated bird character. LLMs use such vector embedding spaces, which are numerical representations of objects in highly dimensional spaces, to understand, process, and generate information. For example, imagine an educational application designed to teach children about wildlife. If a student prompts the chatbot to provide images of birds in a cartoon representation, the LLM will search and generate information from the bottom right quadrant:
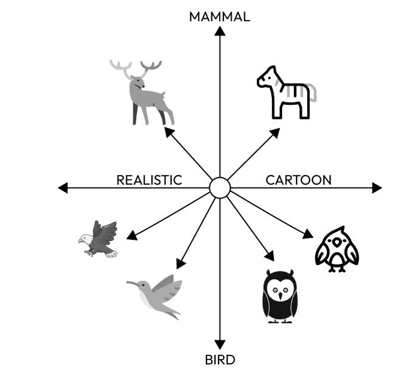
Figure 4.3 – Location of animals with similar characteristics in a highly
dimensional space, demonstrating “relatedness”
Now, let’s delve into the evolution of embedding models that produce embeddings, a.k.a numerical representations of objects, within highly dimensional spaces. Embedding models have experienced significant evolution, transitioning from the initial methods that mapped discrete words to dense vectors, such as word-to-vector (Word2Vec), global vectors for word representation (GloVe), and FastText to more sophisticated contextual embeddings using deep learning architectures. These newer models, such as embeddings from language models (ELMos), utilize long short-term memory (LSTM)-based structures to offer context-specific representations. The newer transformer architecture-based embedding models, which underpin models such as bidirectional encoder representations from transformers (BERT), generative pre-trained transformer (GPT), and their subsequent iterations, marked a revolutionary leap over predecessor models.
These models capture contextual information in unparalleled depth, enabling embeddings to represent nuances in word meanings based on the surrounding context, thereby setting new standards in various natural language processing tasks.
Important note:
In Jan 2024, OpenAI announced two third-generation embedding models, text-embedding-3-small and text-embedding-3-large, which are the newest models that have better performance,lower costs, and better multi -lingual retrieval and parameters to reduce the overall size of dimensions when compared to predecessor second-generation model, text-embedding-ada-002. Another key difference is the number of dimensions between the two generations. The third-generation models come in different dimensions, and the highest they can go up to is 3,072. As of Jan 2024, we have seen more production workloads using text-embedding-ada-002 in production, which has 1,536 dimensions. OpenAI recommends using the third-generation models going forward for improved performance and reduced costs.
We also wanted you to know that while OpenAI’s embedding model is one of the most popular choices when it comes to text embeddings, you can find the list of leading embedding models on Hugging Face (https://huggingface.co/spaces/mteb/leaderboard).
The following snippet of code gives an example of generating Azure OpenAI endpoints:
import openai
openai.api_type = “azure”
openai.api_key = YOUR_API_KEY
openai.api_base = “https://YOUR_RESOURCE_NAME.openai.azure.com” openai.api_version = “YYYY-MM-DD” ##Replace with latest version
response = openai.Embedding.create (
input=”Your text string goes here”,
engine=”YOUR_DEPLOYMENT_NAME”
)
embeddings = response[‘data’][0][’embedding’] print(embeddings)
In this section, we highlighted the significance of vector embeddings. However, their true value emerges when used effectively. Hence, we’ll now dive deep into indexing and vector search strategies, which are crucial for optimal data retrieval in the RAG workflow.
Leave a Reply