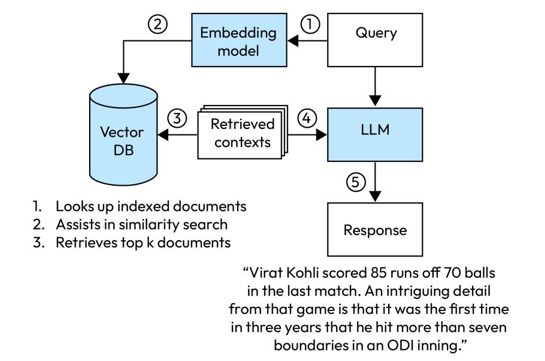
Vector DB sample scenario – Music recommendation system using a vector database
Let’s consider a music streaming platform aiming to provide song recommendations based on a user’s current listening. Imagine a user who is listening to “Song X” on the platform.
Behind the scenes, every song in the platform’s library is represented as a highly dimensional vector based on its musical features and content, using embeddings. “Song X” also has its vector representation. When the system aims to recommend songs similar to “Song X,” it doesn’t look for exact matches (as traditional databases might). Instead, it leverages a vector DB to search for songs with vectors closely resembling that of “Song X.” Using an ANN search strategy, the system quickly sifts through millions of song vectors to find those that are approximately nearest to the vector of “Song X.” Once potential song vectors are identified, the system employs similarity measures, such as cosine similarity, to rank these songs based on how close their vectors are to “Song X’s” vector. The top-ranked songs are then recommended to the user.
Within milliseconds, the user gets a list of songs that musically resemble “Song X,” providing a seamless and personalized listening experience. All this rapid, similarity-based recommendation magic is powered by the vector database’s specialized capabilities.
Common vector DB applications
- Image and video similarity search: In the context of image and video similarity search, a vector DB specializes in efficiently storing and querying highly dimensional embeddings derived from multimedia content. By processing images through deep learning models, they are converted into feature vectors, a.k.a embeddings, that capture their essential characteristics. When it comes to videos, an additional step may need to be carried out to extract frames and then convert them into vector embeddings. Contrastive language-image pre-training (CLIP) from OpenAI is a very popular choice for embedding videos and images. These vector embeddings are indexed in the vector DB, allowing for rapid and precise retrieval when a user submits a query. This mechanism powers applications such as reverse image and video search, content recommendations, and duplicate detection by comparing and ranking content based on the proximity of their embeddings.
- Voice recognition: Voice recognition with vectors is akin to video vectorization. Analog audio is digitized into short frames, each representing an audio segment. These frames are processed and stored as feature vectors, with the entire audio sequence representing things such as spoken sentences or songs. For user authentication, a vectorized spoken key phrase might be compared to stored recordings. In conversational agents, these vector sequences can be inputted into neural networks to recognize and classify spoken words in speech and generate responses, similar to ChatGPT.
- Long-term memory for chatbots: Virtual database management systems (VDBMs) can be employed to enhance the long-term memory capabilities of chatbots or generative models. Many
generative models can only process a limited amount of preceding text in prompt responses, which results in their inability to recall details from prolonged conversations. As these models don’t have inherent memory of past interactions and can’t differentiate between factual data and user-specific details, using VDBMs can provide a solution for storing, indexing, and referencing previous interactions to improve consistency and context-awareness in responses.
This is a very important use case and plays a key role in implementing RAG, which we will discuss in the next section.