Vector DB limitations
- Accuracy vs. speed trade-off: When dealing with highly dimensional data, vector DBs often face a trade-off between speed and accuracy for similarity searches. The core challenge stems from the computational expense of searching for the exact nearest neighbors in large datasets. To enhance search speed, techniques such as ANNs are employed, which quickly identify “close enough” vectors rather than the exact matches. While ANN methods can dramatically boost query speeds, they may sometimes sacrifice pinpoint accuracy, potentially missing the true nearest vectors. Certain vector index methods, such as product quantization, enhance storage efficiency and accelerate queries by condensing and consolidating data at the expense of accuracy.
- Quality of embedding: The effectiveness of a vector database is dependent on the quality of the vector embedding used. Poorly designed embeddings can lead to inaccurate search results or missed connections.
- Complexity: Implementing and managing vector databases can be complex, requiring specialized knowledge about vector search strategy indexing and chunking strategies to optimize for specific use cases.
Vector libraries
Vector databases may not always be necessary. Small-scale applications may not require all the advanced features that vector DBs provide. In those instances, vector libraries become very valuable. Vector libraries are usually sufficient for small, static data and provide the ability to store in memory, index, and use similarity search strategies. However, they may not provide features such as CRUD support, data replication, and being able to store data on disk, and hence, the user will have to wait for a full import before they can query. Facebook’s FAISS is a popular example of a vector library.
As a rule of thumb, if you are dealing with millions/billions of records and storing data that are changing frequently, require millisecond response times, and more long-term storage capabilities on disk, it is recommended to use vector DBs over vector libraries.
Vector DBs vs. traditional databases – Understanding the key differences
As stated earlier, vector databases have become pivotal, especially in the era of generative AI, because they facilitate efficient storage, querying, and retrieval of highly dimensional vectors that are nothing but numerical representations of words or sentences often produced by deep learning models. Traditional scalar databases are designed to handle discrete and simple data types, making them ill-suited for the complexities of large-scale vector data. In contrast, vector databases are optimized for similar searches in the vector space, enabling the rapid identification of vectors that are “close” or “similar” in highly dimensional spaces. Unlike conventional data models such as relational databases, where queries commonly resemble “retrieve the books borrowed by a particular member” or “identify the items currently discounted,” vector queries primarily seek similarities among vectors based on one or more reference vectors. In other words, queries might look like “identify the top 10 images of dogs similar to the dog in this photo” or “locate the best cafes near my current location.” At retrieval time, vector databases are crucial, as they facilitate the swift and precise retrieval of relevant document embeddings to augment the generation process. This technique is also called RAG, and we will learn more about it in the later sections.
Imagine you have a database of fruit images, and each image is represented by a vector (a list of numbers) that describes its features. Now, let’s say you have a photo of an apple, and you want to find similar fruits in your database. Instead of going through each image individually, you convert your apple photo into a vector using the same method you used for the other fruits. With this apple vector in hand, you search the database to find vectors (and therefore images) that are most similar or closest to your apple vector. The result would likely be other apple images or fruits that look like apples based on the vector representation.
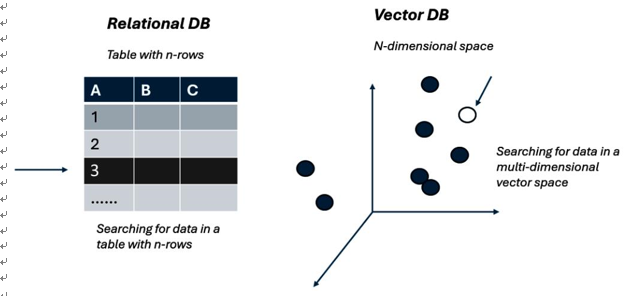
Figure 4.10 – Vector represenation
Leave a Reply