Vector search strategies
Vector search strategies are crucial because they determine how efficiently and accurately highly dimensional data (such as embeddings) can be queried and retrieved. Optimal strategies ensure that the most relevant and contextually appropriate results are returned. In vector-based searching, there are primarily two main strategies: exact search and approximate search.
Exact search
The exact search method, as the term suggests, directly matches a query vector with vectors in the database. It uses an exhaustive approach to identify the closest neighbors, allowing minimal to no errors.
This is typically what the traditional KNN method employs. Traditional KNNs utilize brute force methods to find the K-nearest neighbors, which demands a thorough comparison of the input vector with every other vector in the dataset. Although computing the similarity for each vector is typically quick, the process becomes time-consuming and resource-intensive over extensive datasets because of the vast number of required comparisons. For instance, if you had a dataset of one million vectors and wanted to find the nearest neighbors for a single input vector, the traditional KNN would require one million distance computations. This can be thought of as looking up a friend’s phone number in a phone book by checking each entry one by one rather than using a more efficient search strategy that speeds up the process, which we will discuss in the next section.
Approximate nearest neighbors (ANNs)
In modern vector DBs, the search strategy known as ANN stands out as a powerful technique that quickly finds the near-closest data points in highly dimensional spaces, potentially trading off a bit of accuracy for speed. Unlike KNN, ANN prioritizes search speed at the expense of slight accuracy. Additionally, for it to function effectively, a vector index must be built beforehand.
The process of vector indexing
The process of vector indexing involves the organization of embeddings in a data structure called an index, which can be traversed quickly for retrieval purposes. Many ANN algorithms aid in forming a vector index, all aiming for rapid querying by creating an efficiently traversable data structure. Typically, they compress the original vector representation to enhance the search process.
There are numerous indexing algorithms, and this is an active research area. ANNs can be broadly classified into tree-based indexes, graph-based indexes, hash-based indexes, and quantization-based indexes. In this section, we will cover the two most popular indexing algorithms. When creating an LLM application, you don’t need to dive deep into the indexing process since many vector databases provide this as a service to you. But it’s important to choose the right type of index for your specific needs to ensure efficient data retrieval:
- Hierarchical navigable small world (HNSW): This is a method for approximate similarity search in highly dimensional spaces. HNSW is a graph-based index that works by creating a hierarchical graph structure, where each node represents a data point, and the edges connect similar data points. This hierarchical structure allows for efficient search operations, as it narrows down the search space quickly. HNSW is well suited for similarity search use cases, such as content-based recommendation systems and text search.
If you wish to dive deeper into its workings, we recommend checking out this research paper: https://arxiv.org/abs/1603.09320.
The following image is a representation of the HNSW index:

Figure 4.4 – Representation of HNSW index
The image illustrates the HNSW graph structure used for efficient similarity searches. The graph is constructed in layers, with decreasing density from the bottom to the top. Each layer’s characteristic radius reduces as we ascend, creating sparser connections. The depicted search path, using the red dotted lines, showcases the algorithm’s strategy; it starts from the sparsest top layer, quickly navigating vast data regions, and then refines its search in the denser lower layers, minimizing the overall comparisons and enhancing search efficiency.
- Facebook AI Similarity Search (FAISS): FAISS, developed by Facebook AI Research, is a library designed for the efficient similarity search and clustering of highly dimensional vectors. It uses product quantization to compress data during indexing, accelerating similarity searches in vast datasets. This method divides the vector space into regions known as Voronoi cells, each symbolized by a centroid. The primary purpose is to minimize storage needs and expedite searches, though it may slightly compromise accuracy. To visualize this, consider the following image. The Voronoi cells denote regions from quantization, and the labeled points within these cells are the centroids or representative vectors. When indexing a new vector, it’s aligned with its closest centroid. For searches, FAISS pinpoints the probable Voronoi cell containing the nearest neighbors and then narrows down the search within that cell, significantly cutting down distance calculations:
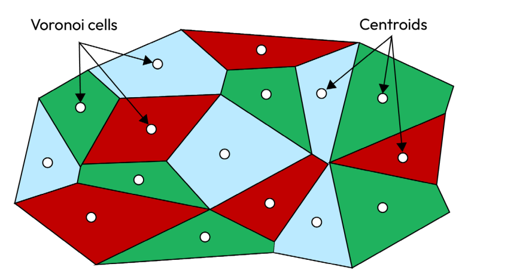
Figure 4.5 – Representation of FAISS index
It excels in applications such as image and video search, recommendation systems, and any task that involves searching for nearest neighbors in highly dimensional spaces because of its performance optimizations and built-in GPU optimization.
In this section, we covered indexing and the role of ANNs in index creation. Next, we’ll explore similarity measures, how they differ from indexing, and their impact on improving data retrieval.
Leave a Reply