When to Use HNSW vs. FAISS
Use HNSW when:
- High precision in similarity search is crucial.
- The dataset size is large but not at the scale where managing it becomes impractical for HNSW.
- Real-time or near-real-time search performance is required.
- The dataset is dynamic, with frequent updates or insertions.
- Apt for use cases involving text like article recommendation systems
Use FAISS when:
- Managing extremely large datasets (e.g., billions of vectors).
- Batch processing and GPU optimization can significantly benefit the application.
- There’s a need for flexible trade-offs between search speed and accuracy.
- The dataset is relatively static, or batch updates are acceptable.
- Apt for use cases like image and video search.
Note
Choosing the right indexing strategy hinges on several critical factors, including the nature and structure of the data, the types of queries (e.g. range queries, nearest neighbors, exact search) to be supported, and the volume and growth of the data. Additionally, the frequency of data updates (e.g., static vs dynamic) the dimensionality of the data, performance requirements (real-time, batch), and resource constraints play significant roles in the decision-making process.
Similarity measures
Similarity measures dictate how the index is organized, and this makes sure that the retrieved data are highly relevant to the query. For instance, in a system designed to retrieve similar images, the index might be built around the feature vectors of images, and the similarity measure would determine which images are “close” or “far” within that indexed space. The importance of these concepts is two-fold: indexing significantly speeds up data retrieval, and similarity measures ensure that the retrieved data is relevant to the query, together enhancing the efficiency and efficacy of data retrieval systems. Selecting an appropriate distance metric greatly enhances the performance of classification and clustering tasks. The optimal similarity measure is chosen based on the nature of the data input.
In other words, similarity measures define how closely two items or data points are related. They can be broadly classified into distance metrics and similarity metrics. Next, we’ll explore the three top similarity metrics for building AI applications: cosine similarity and Euclidean and Manhattan distance.
- Similarity metrics – Cosine similarity: Cosine similarity, a type of similarity metric, calculates the cosine value of the angle between two vectors, and OpenAI suggests using it for its models to measure the distance between two embeddings obtained from text-embedding-ada-002. The higher the metric, the more similar they are:
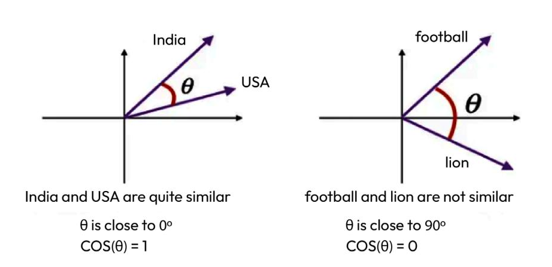
Figure 4.6 – Illustration of relatedness through cosine similarity between two words
The preceding image shows a situation where the cosine similarity is 1 for India and the USA because they are related, as both are countries. In the other image, the similarity is 0 because football is not similar to a lion.
- Distance metrics – Euclidean (L2): Euclidean distance computes the straight-line distance between two points in Euclidean space. The higher the metric, the less similar the two points are:
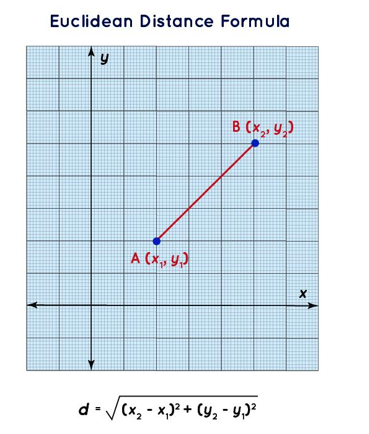
Figure 4.7 – Illustration of Euclidean distance
Leave a Reply